
Data wrangling and data cleaning are both essential steps in the data preparation process, but they serve slightly different purposes.
- Data Cleaning:
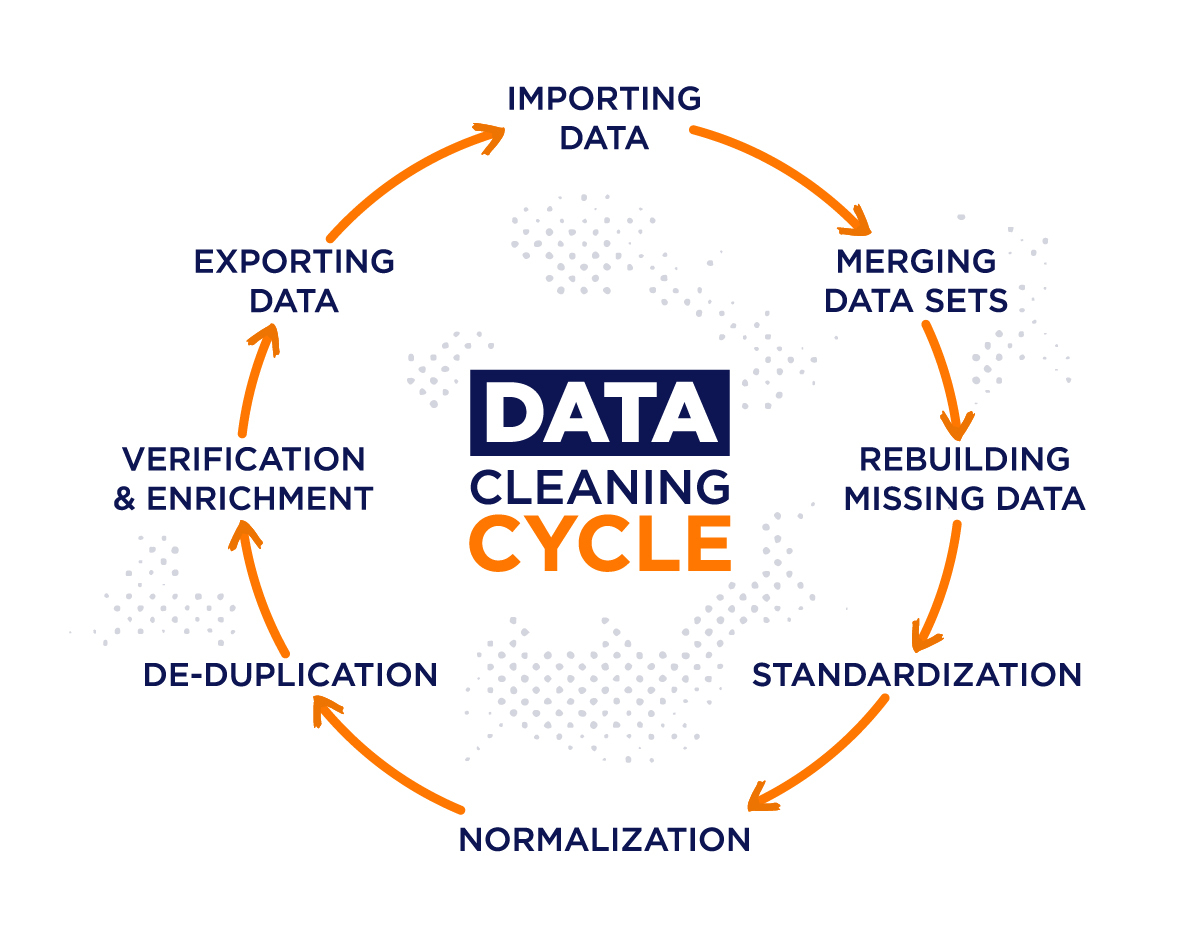
- Objective: Data cleaning focuses on identifying and correcting errors, inconsistencies, and inaccuracies in the dataset.
- Process: This involves tasks such as handling missing values, removing duplicates, correcting typos or formatting errors, and addressing outliers.
- Example: Removing rows with missing values, correcting misspelled names, standardizing date formats.
- Data Wrangling:
- Objective: Data wrangling involves the process of transforming and mapping data from its raw form into a more structured format suitable for analysis.
- Process: This includes tasks such as merging datasets, reshaping data, aggregating data, and creating new variables.
- Example: Joining datasets together, pivoting data from wide to long format, creating calculated fields. Read about What Is Twilio
Understanding Data Wrangling
Data wrangling involves the process of transforming and mapping raw data into a usable format suitable for analysis. It encompasses various tasks such as data extraction, cleaning, transformation, and loading (ETL). The primary goal of data wrangling is to make the data more accessible and organized for analysis purposes.

Exploring Data Cleaning
On the other hand, data cleaning focuses specifically on identifying and rectifying errors or inconsistencies in the dataset. This includes tasks like removing duplicate entries, handling missing values, correcting inaccuracies, and dealing with outliers. The aim of data cleaning is to ensure that the dataset is accurate, consistent, and free from any anomalies that could skew analysis results. Discover about Is GitHub Safe
Key Differences Between Data Wrangling and Data Cleaning
While both data wrangling and data cleaning share the common objective of preparing data for analysis, they differ in terms of their focus and methods employed. Data wrangling is more concerned with restructuring and transforming data, whereas data cleaning primarily deals with identifying and rectifying errors or anomalies in the dataset.
Importance of Data Wrangling and Cleaning in Data Science
Data wrangling and cleaning play pivotal roles in the field of data science by ensuring the quality and reliability of the data being analyzed. By addressing issues such as missing values, inconsistencies, and outliers, these processes help improve the accuracy and credibility of analysis results. Learn about What is LLM Data Science
Challenges in Data Wrangling and Cleaning
Despite their importance, data wrangling and cleaning come with their own set of challenges. Data inconsistency, missing values, and outliers are common issues that data scientists encounter during these processes. Addressing these challenges requires careful consideration and the application of appropriate techniques and tools.
Best Practices for Data Wrangling and Cleaning
To overcome the challenges associated with data wrangling and cleaning, it is essential to follow best practices such as standardization, handling missing data effectively, and implementing robust outlier detection and treatment methods.
Tools and Technologies for Data Wrangling and Cleaning
Several tools and technologies are available to streamline the data wrangling and cleaning process, including popular programming languages such as Python and R, along with dedicated libraries and packages such as Pandas and dplyr.
Real-World Applications of Data Wrangling and Cleaning
Data wrangling and cleaning find applications across various industries, including business analytics, healthcare data management, and financial data processing. These processes are essential for extracting meaningful insights from complex datasets and making informed decisions.
Case Study: Data Wrangling in E-commerce
In an e-commerce setting, data wrangling involves handling vast amounts of transactional data, customer information, and product details. Challenges such as data inconsistency and missing values often arise, requiring sophisticated data wrangling techniques to ensure data accuracy and integrity.
Case Study: Data Cleaning in Healthcare
In the healthcare sector, data cleaning is crucial for maintaining accurate patient records and ensuring the quality of medical data. By addressing issues such as incorrect patient information and duplicate entries, data cleaning helps improve the efficiency of healthcare systems and enhances patient care.
Future Trends in Data Wrangling and Cleaning
As technology continues to evolve, we can expect to see advancements in data wrangling and cleaning processes. Automation, AI, and machine learning integration are poised to play increasingly significant roles, enabling more efficient and effective data preparation and analysis.
Conclusion
In conclusion, data wrangling and data cleaning are integral components of the data analysis process, essential for ensuring the accuracy, reliability, and usability of data. By following best practices and leveraging advanced tools and technologies, organizations can streamline these processes and unlock the full potential of their data assets.
FAQs
- What is the difference between data wrangling and data cleaning?
- Data wrangling involves transforming raw data into a usable format, while data cleaning focuses on identifying and rectifying errors or inconsistencies in the dataset.
- Why is data cleaning important before analysis?
- Data cleaning is essential for ensuring the accuracy and reliability of analysis results by removing errors, inconsistencies, and outliers from the dataset.
- Which tools are commonly used for data wrangling?
- Popular tools for data wrangling include Python libraries such as Pandas and R packages such as dplyr.
- How does data inconsistency affect analysis?
- Data inconsistency can lead to inaccurate analysis results and skewed insights, highlighting the importance of addressing this issue during data preparation.
- Can data cleaning improve machine learning model performance?
- Yes, data cleaning plays a crucial role in improving the performance and accuracy of machine learning models by ensuring that the input data is accurate and reliable.